мШИл•Љ лУ§мЦі, к≥†к∞ЭмЭі 1л∞±лІМ л™ЕмЭі мЮИлЛ§к≥† нХШмЮР. 1л∞± лІМл™ЕмЭА м†БмЦілПД 1нЪМ мЭімГБмЭД мЮРмВђмЭШ мГБнТИ(мДЬлєДмК§ нПђнХ®)мЭД кµђлІ§нХШмШАлЛ§. нХШмІАлІМ к∞Бк∞БмЭШ к≥†к∞ЭмЧР лМАнХі лІИмЉАнМЕ м†ДлЮµмЭД мДЄмЪілЛ§лНШмІА к∞Бк∞БмЭШ к≥†к∞ЭмЭШ нКємД±мЭД нММмХЕнХШмЧђ лМАмЭСнХШлКФ л∞©л≤ХмЭА к∞АлК•нХШкЄ∞лКФ нХШлВШ лґИк∞АлК•нХШлЛ§. мВђмЛ§ к∞АлК•нХШкЄ∞мХЉ нХШмІАлІМ мЖРнХіл•Љ л≥іл©імДЬкєМмІА мЛ§нЦЙнХ† л∞Фл≥ілКФ мЧЖмЬЉлѓАл°Ь мЛ§нШД лґИк∞АлК•мЭілВШ лЛ§л¶ДмЧЖлЛ§. кЈЄлЮШмДЬ к≥†к∞ЭмДЄлґДнЩФлЭЉлУ†мІА нХШлКФ Segramentation мЮСмЧЕмЭД нХШк≤М лРЬлЛ§. лМАнСЬм†БмЬЉл°Ь нХЩкµРмЧРмДЬ мИШ, мЪ∞, лѓЄ, мЦС, к∞Ал°Ь нХЩмГЭлУ§мЭД кµђлґДнХШк≥†, мИШмЧР к∞АкєМмЪЄмИШл°Э 'мЪ∞мИШ'нХЬ нКємД±мЭД к∞Ам°МлЛ§к≥† нМРлЛ®нХЬлЛ§. нХЩкµРмЧРмДЬлКФ 10м†Р лЛ®мЬДл°Ь м™Љк∞ЬмЧИмІАлІМ кЄ∞мЧЕмЧРмДЬлКФ 10м†Р лЛ®мЬДл°Ь м™Љк∞ЬмЧР лН∞мЭінД∞мЭШ нКємД±мЭД нММмХЕнХЬлЛ§лКФ к≤ГмЭА лІ§мЪ∞ мֳ놧мЪі мЭЉмЭілЛ§. лШРнХЬ лН∞мЭінД∞мЭШ лґДнПђк∞А лІ§мЪ∞ лДУмЬЉлѓАл°Ь мЮСмЭА лЛ®мЬДл°Ь м™Љк∞ЬмЧИлЛ§к∞АлКФ м™Љк∞ЬмЦімІД кЈЄл£ємЭі лДИлђі лІОмХД лґДмДЭ мЮРм≤ік∞А мֳ놧мЪЄ к≤ГмЭілЛ§. кЈЄлЯђлЛ§к≥† м£ЉкіАм†БмЭЄ кіАм†РмЧРмДЬ лґДл•ШнХШкЄ∞мЧРлПД лН∞мЭінД∞мЭШ лґДмДЭмЭі мֳ놧мЫМмІДлЛ§.
мЭі лђЄмДЬмЧРмДЬлКФ мЭілЯђнХЬ м£ЉкіАм†БмЭЄ нМРлЛ®мЭД мВђмЪ©нХШмІА мХКк≥†, нЖµк≥ДнХЩм†БмЭЄ л∞©л≤ХмЬЉл°Ь SegmentationнХШлКФ л∞©л≤ХмЭД 2к∞АмІАл•Љ мЖМк∞ЬнХШлПДл°Э нХШк≤†лЛ§.
[edit]
1 лПДмИШлґДнПђнСЬ(нЮИмК§нЖ†кЈЄлЮ®) #
мЦілЦ§ лН∞мЭінД∞к∞А м†Дм≤і м§СмЧР м∞®мІАнХШлКФ мЬДмєШл•Љ мХМмХДлВікЄ∞ мЬДнХімДЬлКФ м†Дм≤і к≤љнЦ•мЭД нММмХЕнХШлКФ мЭЉмЭі лІ§мЪ∞ м§СмЪФнХШлЛ§. м†Дм≤і к≤љнЦ•мЭД нММмХЕнХШлКФлН∞лКФ лПДмИШлґДнПђнСЬк∞А лІ§мЪ∞ мЬ†мЪ©нХШлЛ§. лПДмИШлґДнПђнСЬлКФ лЛ§мЭМк≥Љ к∞ЩмЭА л∞©л≤ХмЬЉл°Ь лІМлУ§ мИШ мЮИлЛ§.
- лН∞мЭінД∞мЭШ мµЬлМА, мµЬмЖМк∞ТмЭД кµђнХЬлЛ§.
- мЮРл£МмЭШ нБђкЄ∞мЧР лФ∞лЭЉ м†БлЛєнХЬ к≥ДкЄЙмЭШ мИШл•Љ м†ХнХЬлЛ§.(мЭімГБмєШлКФ м†Ьк±∞нХЬлЛ§.(мЭімГБмєШ м†Ьк±∞ л∞©л≤Х))
- м§Сл≥µлРШмІА мХКк≤М к≥ДкЄЙмЭШ нБђкЄ∞л•Љ м†ХнХЬлЛ§.
- к∞Б к≥ДкЄЙмЧР мЖНнХШлКФ лПДмИШ(лН∞мЭінД∞ мИШ)л•Љ кµђнХЬлЛ§.
- к≥ДкЄЙмЭА мЧ∞мЖНмЬЉл°Ь нСЬмЛЬнХЬлЛ§.
- мГБлМАлПДмИШл•Љ кµђнХЬлЛ§. (мГБлМАлПДмИШ = нХілЛє к≥ДкЄЙмЭШ лПДмИШ / м†Дм≤і лПДмИШ)
[edit]
2 мК§нКЬмХДмІАмК§ л∞©л≤Х #
мК§нКЬмХДмІАмК§мЭШ л∞©л≤ХмЭА нЖµк≥ДнХЩ м±ЕмЭШ к±∞мЭШ м≤ШмЭМ лґАлґДмЧР лВШмШ§лКФ лВімЪ©мЭілЛ§. мК§нКЬмХДмІАмК§лКФ к≥ДкЄЙмЭШ мИШ[1]л•Љ к≤∞м†ХнХШлКФ л∞©л≤ХмЬЉл°Ь лЛ§мЭМк≥Љ к∞ЩмЭА к≥µмЛЭмЭД лІМлУ§мЧИлЛ§.
- к≥ДкЄЙмЭШ мИШ k = 1 + (log10N / log102) (N; мЮРл£МмЭШ мИШ) = 1 + (LOG10(N) / LOG10(2))
- к≥ДкЄЙмЭШ л≤ФмЬД R = (Maxк∞Т - Minк∞Т) / k
- лН∞мЭінД∞мЭШ міЭ к∞ЬмИШ, Maxк∞Т, Minк∞ТмЭД кµђнХЬлЛ§. мЭі лХМ Maxк∞Т, Minк∞ТмЭД кµђнХ† лХМлКФ мЭімГБмєШл•Љ м†Ьк±∞нХШлКФ к≤ГмЭі мҐЛлЛ§.
- мК§нКЬмХДмІАмК§мЭШ л∞©л≤ХмЭД мЭімЪ©нХШмЧђ к≥ДкЄЙмЭШ мИШ(k)л•Љ кµђнХЬлЛ§.
- мЬЧ лЛ®к≥ДмЧРмДЬ кµђнХімІД к≥ДкЄЙмЭШ мИШ kл•Љ мЭімЪФнХШмЧђ к∞ТмЭШ л≤ФмЬДл•Љ кµђнХЬлЛ§.
- кµђнХімІД л≤ФмЬДл°Ь лН∞мЭінД∞л•Љ кµђлґДнХЬлЛ§.
DECLARE
@k int
, @r bigint
, @avg bigint
, @sigma bigint
, @min bigint
, @max bigint
, @cnt int
, @min_real bigint
, @max_real bigint
--1 + (LOG10(N) / LOG10(2))
SELECT
@sigma = STDEV(Score)
, @avg = AVG(Score)
, @min_real = MIN(Score)
, @max_real = MAX(Score)
FROM #Score
-- мЭімГБмєШ м†Ьк±∞нЫД кµђк∞ДмЭД кµђнХЬлЛ§.: нПЙкЈ† - (1.5 * нСЬм§АнОЄм∞®) ~ нПЙкЈ† + (1.5 * нСЬм§АнОЄм∞®)
SELECT
@r = (MAX(Score) - MIN(Score)) / (1 + (LOG10(COUNT(*)) / LOG10(2)))
, @k = (1 + (LOG10(COUNT(*)) / LOG10(2)))
, @cnt = COUNT(*)
, @min = MIN(Score)
, @max = MAX(Score)
FROM #Score
WHERE Score > @avg - (3 * @sigma)
AND Score < @avg + (3 * @sigma)
;WITH Dumy(Seq)
AS
(
SELECT 1 Seq
UNION ALL
SELECT Seq + 1 FROM Dumy
WHERE Seq + 1 <= @k
), Grade
AS
(
SELECT
(@k - Seq ) + 1 Grade
, @min + ((Seq-1) * @r) BeginScore
, @min + (Seq * @r) EndScore
FROM Dumy
), RealGrade
AS
(
SELECT Grade, BeginScore, EndScore FROM Grade
UNION ALL
SELECT Grade + 1, @min_real, EndScore + 1
FROM Grade
WHERE Grade = (SELECT MAX(Grade) FROM Grade)
UNION ALL
SELECT Grade - 1, BeginScore + 1, @max_real
FROM Grade
WHERE Grade = (SELECT MIN(Grade) FROM Grade)
)
SELECT
B.Grade
, COUNT(*) AccountCnt
, SUM(NetAMT) NetAMT
FROM #Score A
INNER JOIN RealGrade B
ON A.Score BETWEEN B.BeginScore AND B.EndScore
GROUP BY
B.Grade
ORDER BY 1
[edit]
3 нСЬм§АнОЄм∞®л•Љ мЭімЪ©нХШлКФ л∞©л≤Х #
нСЬм§АнОЄм∞®л•Љ мЭімЪ©нХШл©і лЛ®мИЬнЮИ мЪ∞мИШ, л≥інЖµ, мЈ®мХљ мЭіл†Зк≤М 3к∞ЬмЭШ кЈЄл£ємЬЉл°Ь лВШлИМ мИШ мЮИлЛ§. мШИл•Љ лУ§мЦі, 50л™ЕмЭі м†ХмЫРмЭЄ нХЬ нХЩкЄЙмЧРмДЬ нХЩмГЭлУ§мЭШ нВ§мЧР лМАнХЬ нПЙкЈ†мєШк∞А 170CmмЭік≥†, нСЬм§АнОЄм∞®к∞А 7CmмШАмЭД лХМмЧР лЛ§мЭМк≥Љ к∞ЩмЭі лВШлЙ† мИШ мЮИлЛ§. (ѕГ[2]: нСЬм§АнОЄм∞®, ќЉ[3]: нПЙкЈ†)
- мЈ®мХљ: 163Cm лѓЄлІМ (ќЉ - ѕГ)
- л≥інЖµ: 163 ~ 177Cm (68.3%)
- мЪ∞мИШ: 177Cm міИк≥Љ (ќЉ + ѕГ)
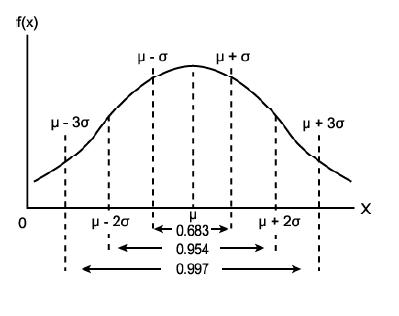 нСЬм§Ам†ХкЈЬлґДнПђ
нСЬм§Ам†ХкЈЬлґДнПђм∞Єк≥†л°Ь '6мЛЬкЈЄлІИ'мЭШ мЛЬкЈЄлІИлКФ мЬДмЭШ кЈЄл¶Љк≥Љ к∞ЩмЭА лЬїмЭД лВінПђнХШк≥† мЮИлЛ§. 6мЛЬкЈЄлІИлКФ (ќЉ - 6ѕГ) ~ (ќЉ + 6ѕГ)мЭШ кµђк∞ДмЭД лЬїмЭД лВШнГАлВЄлЛ§.