![[http]](/moniwiki/imgs/http.png)
[edit]
1 개요 #
- 표와 그래프는 자료분포에 관한 전체적인 정보를 시각적으로 제시하는 기능을 수행
- 자료의 분포가 내포하는 특성들을 하나의 요약 수치(summary measure)로 나타낼 때 통계분석이 의미 있는 결과
- 요약된 하나의 수치를 요약통계량 or 기술 수치(descriptive measure)라고 함
- 자료의 특성을 요약하는 지표
- 집중경향치
- 산포도의 측정치
- 위치의 측정치
- 형태의 측정치
- 집중경향치
[edit]
2 집중경향치(measure of central tendency) #
정의
- 자료의 집중되어 있는 중심위치(center)
- 자료의 중심으로서 자료 전체를 대표할 수 있는 값
- 종류
- 산술평균
- 중앙치
- 최빈치
- 기타등등
- 산술평균
[edit]
2.1 산술평균(arithemtic mean) #
자료 A = {x1, x2,...xn}}이 있을 경우
평균 = (x1 + x2 + ... + xn) / n
단, 각 개별치가 똑같이 중요다든지 또는 두 개 이상의 집단을 비교하는 경우 각 집단의 평균이 똑같이 중요하다는 가정하에 사용할 수 있다. 만약 중요성에 차이가 있다면 가중평균(weighted mean)을 계산하게 된다. 예를 들어 다음과 같이 학점을 받은 경우| 학점 | 과목수 |
| A=4 | 2 |
| B=3 | 1 |
| C=2 | 1 |
| D=1 | 1 |
평균 = (2*4 + 1*3 + 1*2 + 1*1) / 5 = 2.8
[edit]
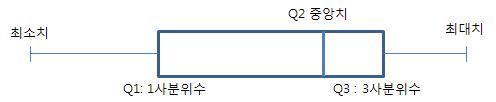
3 중앙치(median) #
median은 양적 자료에만 사용된다. 자료를 순서대로 나열했을 때에 중앙에 위치한 관측치를 말한다. 중앙값 또는 중위수라고도 말한다. 중앙값을 구하는 방법은 다음과 같다.
- 자료를 크기 순서로 나열한다.
- 홀수이면, (n+1)/2 번째 값이 메디안
- 짝수이면, n/2번째와 (n/2 + 1) 번째의 평균값이 메디안이다.
[edit]
4 최빈치(mode) #
최빈치는 자료의 수가 가장 많은 관측치를 말한다. 두 개의 최빈치를 갖는 경우는 쌍봉(bimodal), 세 개 이상의 최빈치를 갖는 경우는 다봉(multimodal)이라고 한다.
[edit]
5 대표치의 선택 #
| 중앙치와 최빈치 | 평균 |
| 자료의 일부만 이용 | 자료크기와 도수까지 고려(모든 자료의 정보를 이용) |
| 수학연산 불가능 | 수학연산 가능 |
| 가중평균 구할 수 없음 | 가중평균 구할 수 있음 |
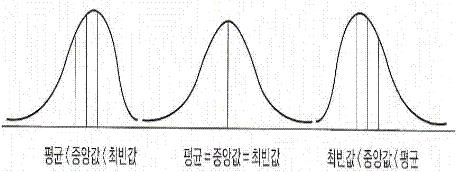
평균은 분산을 계산하고, 모평균 추정, 가설검정 등 통계분석의 대표치로서 가장 널리 사용된다. 하지만 극단적인 이상치(outlier)가 있는 경우에는 크게 영향받는 평균보다는 이에 덜 민감한 중앙치를 대표치로써 사용한다. 자료의 분포가 비대칭적인 경우, 평균과 함께 중앙치를 대표치로 사용한다.
[edit]
6 산포도의 측정치 #
- 집중경향치는 자료의 중심을 구하는 것. 분산도(dispersion)이라고도 함.
- 자료의 흩어짐 정도는 구할 수 없음.
- 수치들의 크고 작음을 변동(variation)이라고 함
- 산포도는 수치들의 변동의 정도를 측정
- 산포도가 크면 클수록 평균과 같은 대표치의 신뢰도는 낮아짐
- 분산의 요약특성치
- 범위
- 중간범위
- 평균절대편차
- 분산
- 표준편차
- 변동계수
- 범위
[edit]
7 범위(range) #
- 최대치 - 최소치
- 두 극단 관측치만 가지고 계산하므로 다른 관측치에 대해서는 아무것도 말해주지 않음
- 자료속의 극단적인 이상치(outlier)에 크게 영향 받음.
[edit]
8 중간범위(mid-range) #
- 자료의 중간 50%인 3사분위수 - 1사분위수
- 자료의 중간 80%인 90백분위수 - 10백분위수
[edit]
9 평균절대편차(mean absolute deviation:MAD) #
- 편차(deviation), 평균으로부터 떨어진 정도 (편차의 합은 항상 0)
- 편차의 합이 0 이되므로 이를 극복하기 위해서 모든 편차의 절대값(|편차|)에 대한 평균 -> 평균절대편차
- 절대값을 계산해야 하므로 통계분석에서는 별로 사용하지 않음
[edit]
10 분산(variance)과 표준편차(standard deviation) #
- 분산, 주어진 각 자료가 그들 자료의 평균주위로 얼마나 집중되어 있는가를 측정
- 분산이 작으면, 변동성이 적음
- 분산이 크면, 변동성이 많음(평균 주위에 분포됨)
- 분산이 작으면, 변동성이 적음
- 모분산 = 편차(평균-자료)의 제곱(squared deviation) / N
- 표본분산 = 편차(평균-자료)의 제곱(squared deviation) / (N-1)
- 모분산이 N이고, 표본분산이 N-1인 이유
- 표본분산에 N을 사용하면 모분산을 과소평가하여 편의추정치(biased estimate)를 제공
- 그러므로 어느 한쪽으로 치우치게 하지 않기 위해서 N-1을 사용한다.
- 표본분산에 N을 사용하면 모분산을 과소평가하여 편의추정치(biased estimate)를 제공
- 분산은 제곱을 하므로 원 자료보다 큰 단위로 표시가 됨. 그래서 제곱근을 구함 -> 표준편차
[edit]
11 체비셰프의 정리 #
- 만약 정규분포가 아니거나 분포를 모를 경우에는 체비셰프의 정리(Chebyshev's theorem)가 적용됨
- -kσ ~ kσ 내에 포함될 자료의 비율은 적어도 전체 자료의 1 - (1/k2)이다. 단, k > 1
- 경험법칙(자료의 분포가 종모양으로 좌우대칭 형태이면)
- -1σ ~ 1σ에는 약 68%의 자료가 있다.
- -2σ ~ 2σ에는 약 95%의 자료가 있다.
- -3σ ~ 3σ에는 약 99%의 자료가 있다.
- -1σ ~ 1σ에는 약 68%의 자료가 있다.
- 예제: A반의 국어점수의 평균은 80점, 표준편차는 5 일 때
- 70 ~ 90 점 사이의 점수를 받은 학생은 전체의 몇 %인가?
- 평균=80, 표준편차=5 이므로, 70점은 2σ, 90점도 2σ이므로 k = 2 이므로, 1 - (1/22) = 0.75 = 75%
- 평균=80, 표준편차=5 이므로, 70점은 2σ, 90점도 2σ이므로 k = 2 이므로, 1 - (1/22) = 0.75 = 75%
- 정규분포라면 몇 %인가?
- 2σ 이므로 95%
- 2σ 이므로 95%
- 70 ~ 90 점 사이의 점수를 받은 학생은 전체의 몇 %인가?
[edit]
12 변동계수 #
두 집단의 단위가 다르거나(연령과 달러의 표준편차 비교) 평균이 큰 차이를 보이는 경우 표준편차를 비교 할 수 없다. 이런 경우 상대적 표준편차 또는 변동계수 (coefficient of variation: CV)를 이용한다.
CV = 표준편차 / 평균