1 결합 인덱스 기본 #
데이터베이스에서 결합(복합) 인덱스는 매우 중요하다. 결합인덱스의 사용이 잘못되었을 때는 결합인덱스를 구성하는 첫 번째 컬럼이 사용되지 않거나, ‘=’ 로 비교되지 않거나, 선택도가 매우 높은데 결합인덱스를 구성하는 중간 컬럼값이 조건에서 빠졌거나의 문제이다. 그러므로 당연히 결합인덱스를 구성하는 첫 번째 컬럼은 항상 사용되어야 하며, 되도록이면 ‘=’ 로 사용되도록 해야 한다. 다음의 예를 보면 알 수 있다.
Select SiteCode, ItemCode From ItemSiteMaster
Where ItemCode = '10001N'
--인덱스 : SiteCode + ItemCode
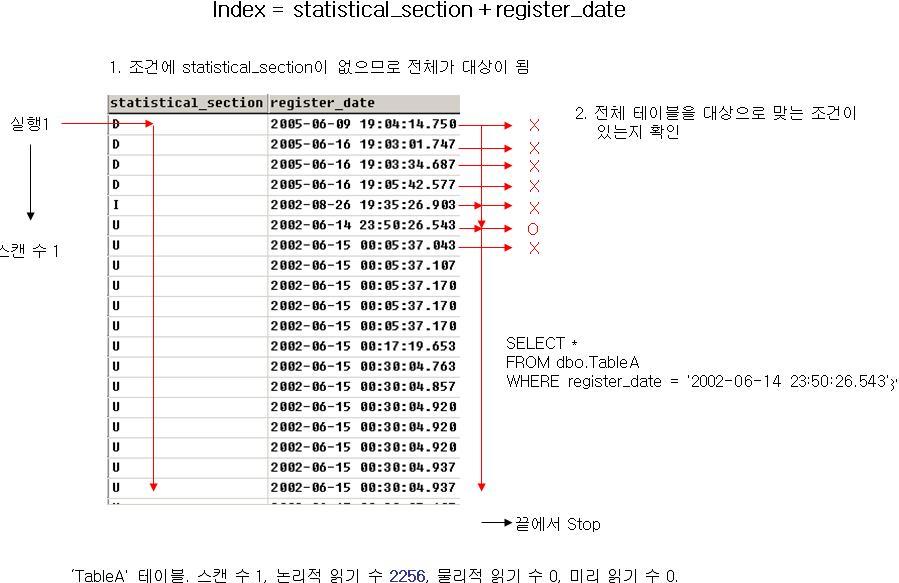
현재
StieCode의 선택도는 1 이다. 즉, 모든 행들에 똑 같은
SiteCode의 값이 들어 있는 것이다. 그래서 일반적으로 생각해 볼 때
SiteCode를 생략해도 충분한 성능을 낼 수 있다는 착각을 하는 것이다. 다음은 위 쿼리를 실행했을 때의 실행계획과 입/출력 양이다. 결과는 1건이다.

'
ItemSiteMaster' 테이블. 스캔 수 1, 논리적 읽기 수 4318, 물리적 읽기 수 0, 미리 읽기 수 0.
실제로 3초도 안 걸려 결과를 볼 수 있다. 그러나 이것은 서버의 사양이 좋을 때의 얘기이다. 위의 논리적 읽기 수 정도되는 것을 MSSQL Server의 최소 사양에 맞춰서 설치한 후 다시 쿼리해 보면 틀려질 것이다. 위 경우
8KB * 4318Page의 입/출력이 일어났으므로 1건을 가져오기 위해서 약 33MB를 읽은 것이다. 그렇다면
SiteCode를 붙인 쿼리는 어떨까?
Select SiteCode, ItemCode From ItemSiteMaster
Where SiteCode = 'N100'
And ItemCode = '10001N'

'
ItemSiteMaster' 테이블. 스캔 수 1, 논리적 읽기 수 3, 물리적 읽기 수 0, 미리 읽기 수 0.
I/O양만 봐도 결합인덱스를 제대로 사용했을 때와 결합인덱스를 구성하는 첫 번째 컬럼을 조건절에서 ‘=’ 로 비교했을 때는 1000배 이상의 차이가 난다. 그럼 Like로 비교했다면 어떨까?
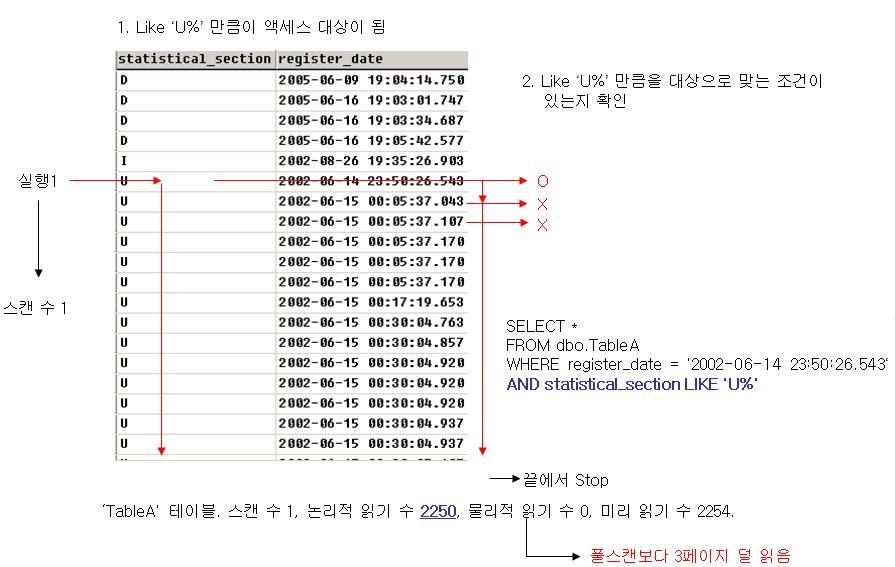
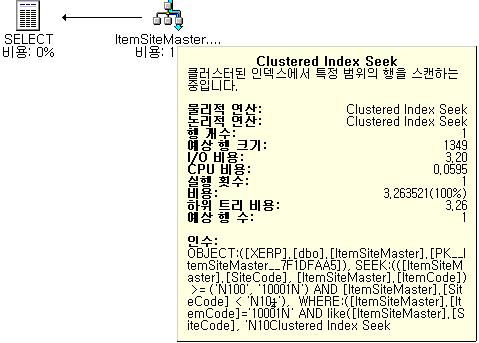
Select * From ItemSiteMaster (index = 1)
Where SiteCode Like 'N100%'
And ItemCode = '10001N'
'
ItemSiteMaster' 테이블. 스캔 수 1, 논리적 읽기 수 4318, 물리적 읽기 수 0, 미리 읽기 수 0.
사용되기는 되었으나 논리적 읽기 수는 똑 같은 것을 볼 수 있다. 이것은
SiteCode의 선택도가 1 이기 때문에서 범위를 줄여주지 못한데 있다.
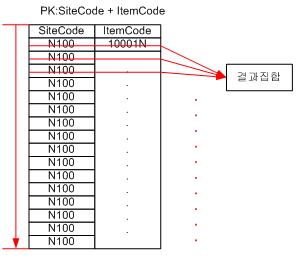
조건절에 Where
SiteCode Like 'N100%' 와 같이 LIKE로 패턴매칭 검색이 이루어진 것은
SiteCode의 값이 모두 ‘N100’ 이고,
ItemCode의 값이 ‘10001N’ 로 찾았더라도, 조건에서
SiteCode가 모두 패턴매칭되므로 끝까지 스캔을 해보아야 하는 것이다. 실행계획을 보면 지금의 것은 Seek 이고, 앞의 경우는 Scan이다. 그렇다면
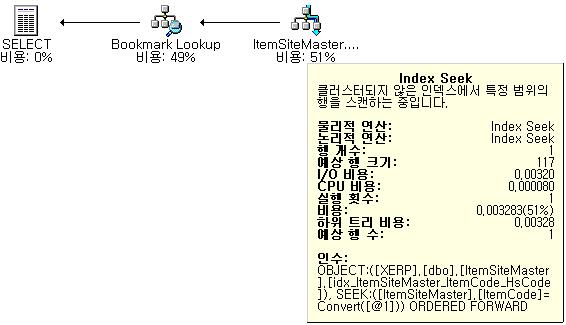
ItemCode를 결합인덱스의 구성하는 첫 번째 컬럼으로 둔다면 어떨까? (논클러스터드 인덱스의 경우)
Select * From ItemSiteMaster
Where ItemCode = '10001N'
'
ItemSiteMaster' 테이블. 스캔 수 1, 논리적 읽기 수 6, 물리적 읽기 수 0, 미리 읽기 수 0.
6페이지를 읽었고, Bookmark Lookup에 대한 비용이 생겼다. Bookmake Lookup이 생기는 이유는 생성된 인덱스가 논클러스터드 인덱스이기 때문이다. 논클러스터드 인덱스는 데이터를 직접 접근하지 못하기 때문에 리프노드가 클러스터드 인덱스의 리프노드의 실제 데이터를 가리키는 행로케이터이기 때문이다. 그러므로 Bookmark Lookup은 흔히 이야기하는 랜덤 액세스가 발생하는 것이다. 다음과 같이 결합인덱스를 구성하는 첫 번째 컬럼을 ‘=’로 비교하고, 다음 컬럼을 Like로 비교하면 선택도만 좋다면 좋은 실행계획이 나온다.
Select * From ItemSiteMaster
Where SiteCode = 'N100'
And ItemCode Like '100%'

'
ItemSiteMaster' 테이블. 스캔 수 1, 논리적 읽기 수 9, 물리적 읽기 수 0, 미리 읽기 수 0.
2 중간에 이빨이 빠진 조건인 경우 #
위의 경우 결합인덱스는 2개의 컬럼으로 구성된다. 만약 3개 이상의 컬럼으로 구성되는데 중간 컬럼값이 조건에서 없다면 결합인덱스를 구성하는 첫 번째 컬럼의 조건의 범위를 모두 스캔해야 한다. 그러므로 결합인덱스를 생성할 때의 순서는 매우 중요하다. 다음 예제를 보면 그 뜻을 분명히 이해할 수 있을 것이다.
--인덱스: SiteCode + RetNorGubun + yyyymm + EmpCode + PayItemCode
--중간에 yyyymm 컬럼에 대한 조건을 주지 않음
Select top 100 SiteCode, RetNorGubun, yyyymm, EmpCode, PayItemCode
From hrPayMaster
Where SiteCode = 'N100'
And RetNorGubun = 'NOR'
And EmpCode = '001001'
And PayItemCode = 'D0000'

'hrPayMaster' 테이블. 스캔 수 1, 논리적 읽기 수 14181, 물리적 읽기 수 0, 미리 읽기 수 903.
중간에 ‘yyyymm’ 컬럼에 대한 조건을 빠뜨렸다. Clustered Index Seek를 했음에도 불구하고, ‘yyyymm’ 컬럼이 결정되지 않아 19개의 행을 가져오기 위해 무려 14181 페이지나 읽어야 했다. 현재 이와 같은 쿼리플랜을 사용하지 않는다. 왜냐하면 필자가 선택도가 좋은 다른 인덱스를 생성해 주었기 때문이다. 실제로 이러한 결합인덱스를 구성하는 값이 조건절에서 없는 것에 대한 해결은 인덱스의 순서를 조정하면 해결된다.
![[-]](/moniwiki/imgs/plugin/arrup.png "[-]")
![[+]](/moniwiki/imgs/plugin/arrdown.png "[+]")